
Oct 10-15: KP2/EA8DBM Oct 16-20: VP2V/LY3UM Oct 22-26: VP2MBM Oct 28-31: V2/EA8DBM Nov 1- 3: PJ7/EA8DBM Nov 4-9: PJ5/EA8DBM Nov 10-13: FS/EA8DBM Nov 14-18: FJ/EA8DBM Nov 19-24: KP4/EA8DBM
OPs
Rune LA7THA, Gjermund LB5GI, Erwann LB1QI,
Svein LA3BO, Morten LB8DC, Chris LA8OM,
Philipp OE7PGI, Svein Jarle LA9KKA, Torvald LB1FI

Italian Dxpedition Team TT8 WebPage
Log check and QSL request

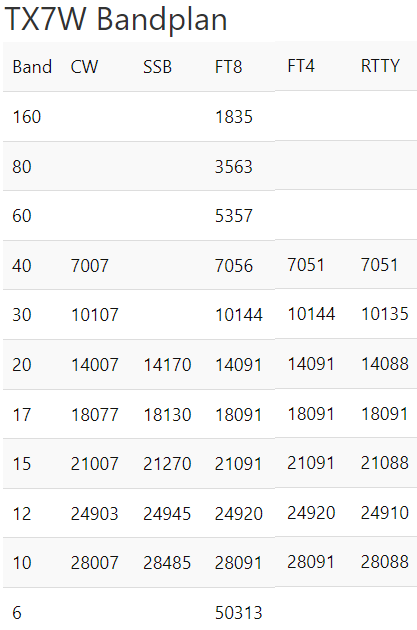

by DJ9RR, EI2II, EI2JD, EI3ISB, EI3IXB, EI4HH, EI5GM,EI5GSB, EI6FR, EI8KN, EI9HQ, EI9FBB and PA3EWP.
8 stations from 160m -10m on CW, SSB and Digital.
CB0ZEW Remote Station(NexGenRiB) WSJT-X F/H Mode
CB0ZA On Island Station MSHV F/H Mode

http://momo.gmobb.jp/fcz_ac1/
http://momo.gmobb.jp/fcz_ac2/
しかし、多数のファイルをポチポチとダウンロードするのは手間が
かかりますので、Pythonで自動ダウンロードするプログラムを書き
ました。私の書いたものはちょっとダサいものですが、1回動かせば
もう動かすことはほぼないプログラムですので、気の利いたコーディ
ングにするモチベーションもあがりません。作りっぱなしのプログラ
ムそのままでの公開です。
以下のプログラムをコピーして、ウインドウズのメモ帳などにペース
トして。適当なプログラム名に拡張子として".py"を付けて(例えば、
fcz_download.pyというファイル名で)、pdfファイルをダウンロード
するフォルダに保存しておきます。
プログラムをダブルクリックすれば、pdfファイルのダウンロードが
始まります。
プログラムの中心部分は下のページからの借用です。このプログラム
は素晴らしいものです。
https://degitalization.hatenablog.jp/entry/2020/08/02/193536
準備
(1) Pythonのインストール
(2) コンソール画面でpy -m pip install beautifulsoup4と入力して
beautifulsoupをインストールする。
(3) py -m pip install urllibと入力してurllibをインストールする。
# ---- プログラム本体はここから下 ----
from bs4 import BeautifulSoup
import urllib.request as req
import urllib
base_url1 = "http://momo.gmobb.jp/fcz_ac1/"
url1 = base_url1 + "001-050.htm"
url2 = base_url1 + "051-100.html"
url3 = base_url1 + "101-150.htm"
url4 = base_url1 + "151-200.htm"
base_url2 = "http://momo.gmobb.jp/fcz_ac2/"
url5 = base_url2 + "175-200.htm"
url6 = base_url2 + "201-250.htm"
url7 = base_url2 + "251-300.html"
url8 = base_url2 + "cirq_contents.htm"
def download(URL):
link_list =[]
for link in result:
href = link.get("href")
link_list.append(href)
pdf_list = [temp for temp in link_list if temp.endswith('pdf')]
for filename in pdf_list:
urlData = URL + urllib.parse.quote(filename)
new_filename = filename[filename.find("/")+1:]
#print(filename)
#print(urlData)
print(new_filename)
data = req.urlopen(urlData).read()
with open(new_filename, mode="wb") as f:
f.write(data)
for url in [url1, url2, url3, url4]:
res = req.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
result = soup.select("a[href]")
download(base_url1)
for url in [url5, url6, url7, url8]:
res = req.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
result = soup.select("a[href]")
download(base_url2)





















